Train Your Ninja
Ninja Gaiden is a nightmare game when I was kid… TL;DR
Ninja Gaiden
This is the ninja game for real ninja. Jump & slash, swift moving and never hesitate. I cannot beat this game as a kid and still struggle today. But now dqn sounds so powerful that we probably got some chances?
 Ninja Gaiden, from Tecmo
Ninja Gaiden, from Tecmo
Wait…
There Are Already a Lot of Nice Stuff for these type of games e.g. Super Mario Bros. It looks this problem is solved (AI beats human). However they are not ninja gaiden ☺︎ . This game is quite special and different from game like super mario. It’s unfriendly to beginner; it has complicate scenes (visually, e.g. strange climb detection and bounding box); it has a few glitches/techniques (multiple slashes, air floor, and damage boost) that makes interesting for AI to explore; a lot of different powerup weapons and ninpo; … Most importantly, having finished readings on this great intro website (recommend for beginner of reinforcement learning), it makes me very curious to see whether career of Ryu/ninja can be replaced by state of art reinforcement learning agent.
OpenAI Gym
Gym is the environment created to train AI on many different games. NES game’s Gym is not officially supported due to some reasons. The quick search leads me to the work like Mario NEAT that uses the Lua script on Fceux. Not a fan of Lua, so I started to look for something in Python.
Finally, I end up with nes-py, which is very pythony and have wiki to help build your own environment. Even though I ran into some trouble building the nes-py package because python setuptools requires some strange CXXFLAGS (-flto-partition=None) that my clang doesn’t like, but eventually I manually built this package with some hacky way in pip temp folders and moved around the *.so in nes-py package. BTW, the author of nes-py also have an example of Super Mario Bro’s nes environment, check it out if interested.
Hack into Ninja Gaiden
Now we need to know where (memory address) is the data (e.g. hit point). Thanks to gamers, we have a nice website named TASVideo documenting a lot. But be aware some of them are not precise enough. For example, to get the x position of Ryu, I checked many the memory location and eventually figured it out it’s a fixed point 3-bit float instead of the 2-bit screen position as in document.
Agents
Now let’s go down to business. I stolen a lot of code from internet here and there. Again before diving, I’d suggest you read through this free intro course to understand the basics of a2c, ppo etc.. I created a simple and cruel reward function to best encourage moving fast to end of the level. No reward to slash enemy or gain ninpo etc. because I really wanted to see an AI speedrunner.
Let’s first only focus on level 1-1.
 Ninja Learning Gaiden
Ninja Learning Gaiden
Here’s my shallow findings after 8 hours training (sorry slow computer) for different models:
- PPO performs not as good as A2C
- A2C stopped maybe due to bugs
- A2C curiority works mostly and even finished the level 1
As non-expert, for these models I cannot really judge good or bad, but only based on the implementation result. None of them surprise me as they did in Super Mario. They seems to be really confused even after training a while. Later probably I should try out the OpenAI’s newly published a2c models. But even with these little experience, I still could get some the state-of-art feeling.
What’s Promising
Climb the Obstacle
Most Agents will stop at the wall, because it doesn’t know how to get there. some can search some just cannot. I’m amazed AI with curiosity can actually figure out the wall climb jump. For human, it’s really hard to do that since this behavior (control) is not quite human anyway.
 Ninja can climb
Ninja can climb
Powerup Items
Also thumb up for the self-motivated behavior to slash the ninpo even though I didn’t give it as reward. Maybe the agent is just do it for fun ☺︎ .
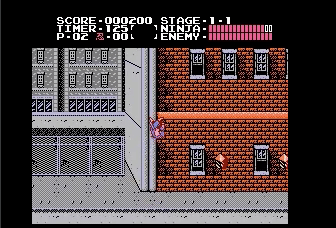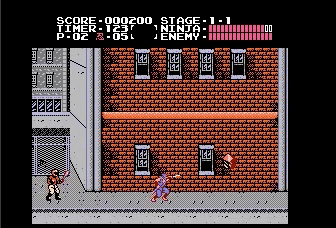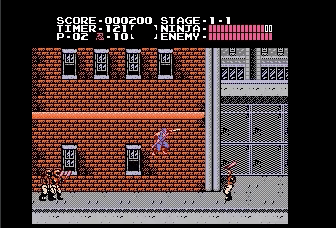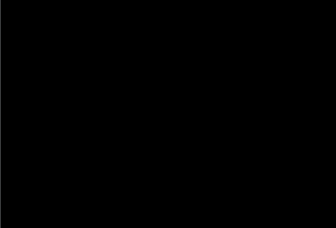 Ninja blindly loves powerup :)
Ninja blindly loves powerup :)
Finding Secrets/Bugs
AI even can jump on air floor which is usually done by speedrunners.
Challenges
Fight Tyson
Tyson is annoying for AI and beginners too. Sometimes, AI is just like a scared cat in the tree.
Strategy Thinking
Probably Super Mario is no brainer game, player doesn’t need to think about strategy too much: all rewards can be achieved in very short time period or strategy is very easy to discover. But in this Ninja Gaiden, strategically gain Ninpo and other weapons can largely improve performance. Unfortunately, I didn’t see any hopes for all the models I tested.
Real Ninja vs AI
First of all, human are still fine. At this point, AI cannot beat human or even beginners with a few min training. A long way to go! Also depending on game’s genre, the more strategic the more hard for AI because they only have visual clues. Not like us, we’ve been educated from different kinds of source (visual, sound, feel…) since born. But AI can do really well in visual game and not suprisingly better than human because they can try different ways again and again and operate much faster than human.
Look at this speedrunner, human’s proud!
A Few Rough Ideas So Far
- AI probably could have seen better given better emulator environment. NES game has limitation to show multiple enemy in same screen nor does it have alpha blending. You’ll see blinking sprite from time to time. This probably annoys AI a bit.
- Multitask or modularization (components) helps. For example a better visual detection to identify the enemy and a thinker network with more memory to think strategy.
- I feel curiosity is a key factor to avoid local optimal and we should keep trying a lot in limited time.
- Human teacher will definitely help boost the performance. This is perhaps why Go players like Lee Sedol cannot win AI cause we give them the optimal searching path we human found through years of training experience and computer is faster to process number/arithm than us
atop of our experience. It’s not a fair game at all from this pov. But I really appreciate our Go players to help promote AI techniques. Same idea can apply if we have our speed runners to teach computer and then they can beat us by searching and improving the margins. - Perhaps within our era, AI without a huge team behind is still primitive.
- Purely relying on visual clues is like we human only trust our vision hunch (muscle memory?). It won’t make us stand out in more strategical competition like DoTA. In these games, human sometimes can sacrifice some short time low reward to gain something bigger, and this experience is learnt from other resources after we are born.